K8s HPA
HPA全称Horizontal Pod Autoscaling,是K8s实现pod自动水平扩容缩容的特性,这个特性使整个kubernetes集群马上高大上起来了。
要使用HPA也不是这么简单的,HPA api分v1、v2beta1、v2bate2三种,v1只支持通过CPU衡量扩缩容,v2bate1加入针对内存作为度量,v2bate2可以用customer metrics例如网络等,所以v2bate1开始才比较实用。
HPA能控制rc、deployment等resource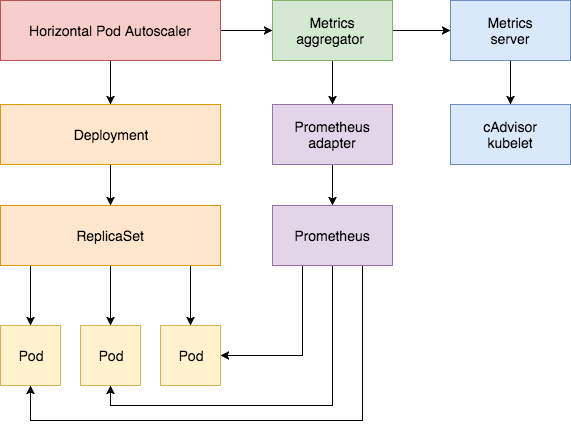
要使用HPA必须要开启以下两个特性:
- Aggregation Layer 聚合层,通过与核心的apiserver分离,实现自定义的扩展功能
- metrics-server 数据收集,能够收集pod、node等实时运行指标(cpu、内存),给k8s集群使用,例如kubectl top命令、HPA
比较老的版本使用heapster
Aggregation Layer
要打开Aggregation Layer,需要配置一下apiserver,增加相关认证证书。认证流程是client发起请求到apiserver,apiserver与aggergated apiserver建立tls安全链接,把请求proxy到aggergated apiserver,继续进行–requestheader-*参数的相关认证。
认证流程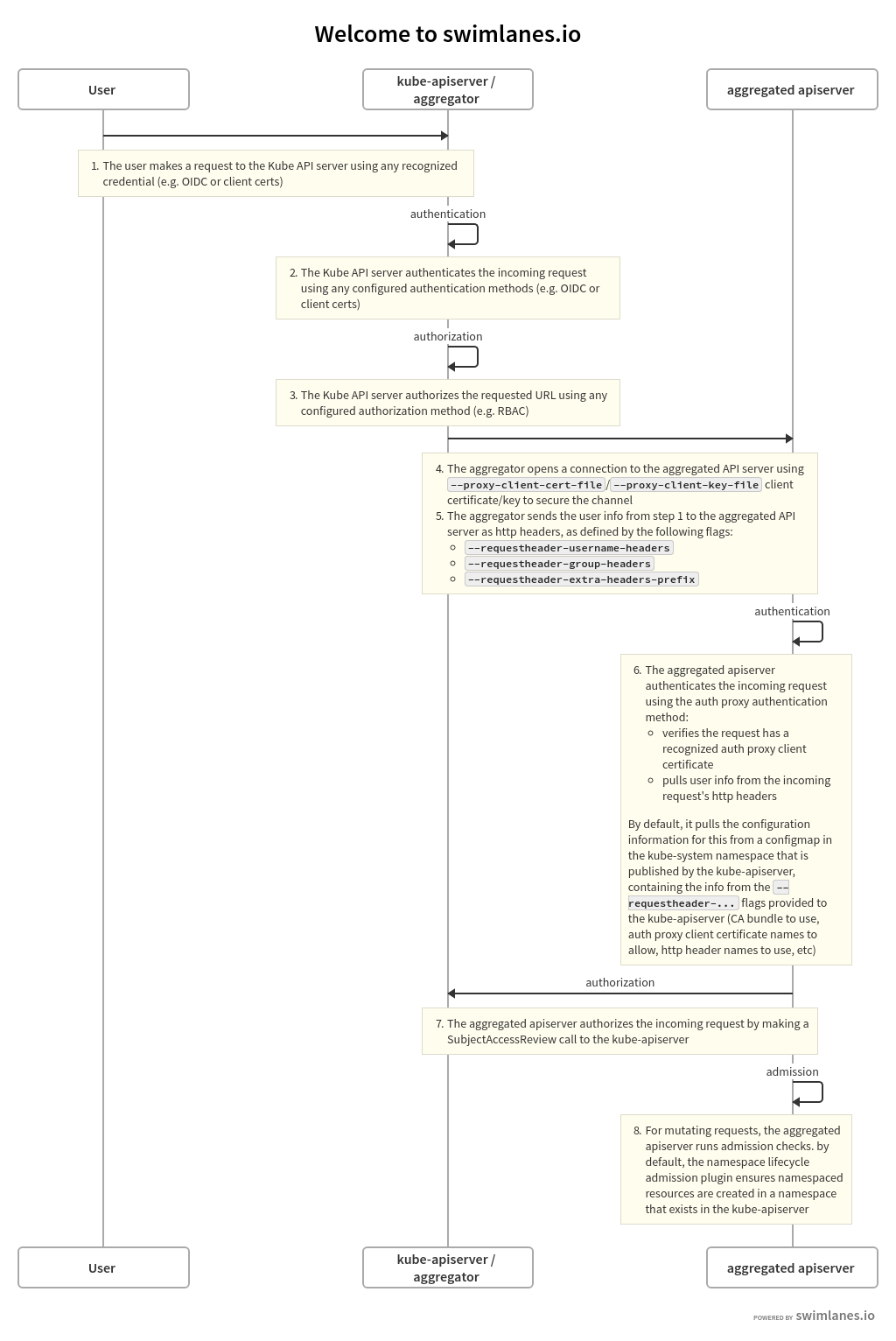
转自k8s官方
需要生成aggregate使用的证书,参考cfssl生成证书方法,proxy-client-cert-file的CN需要与requestheader-allowed-names匹配。
在apiserver增加如下启动参数
1 | --requestheader-client-ca-file=/etc/kubernetes/pki/agg-ca.pem |
metrics server
从k8s 1.8开始,集群的资源使用情况都通过metrics api收集,例如容器CPU、内存。这些指标可用于kuberctl top或者k8s的HPA等特性。
metrice server可以在github找到并部署
1 | git clone https://github.com/kubernetes-incubator/metrics-server |
- 注1:metrics-server默认使用node的主机名,但是coredns里面没有物理机主机名的解析,一种是部署的时候添加一个参数: –kubelet-preferred-address-types=InternalIP,Hostname,InternalDNS,ExternalDNS,ExternalIP,第二种是使用dnsmasq构建一个上游的dns服务
- 注2:kubelet 的10250端口使用的是https协议,连接需要验证tls证书。可以在metrics server启动命令添加参数–kubelet-insecure-tls不验证客户端证书
- 注3:yaml文件中的image地址k8s.gcr.io/metrics-server-amd64:v0.3.3 需要梯子,需要改成中国可以访问的image地址,可以使用aliyun的。这里使用hub.docker.com里的google镜像地址 image: mirrorgooglecontainers/metrics-server-amd64:v0.3.3
成功运行kubectl top命令
1 | ubuntu@k8s-dev-m1:~/k8sssl/agglayer$ kubectl top nodes |
如果出现下面的报错说明你的apiserver不能访问到metrics server,要么把master节点纳入k8s网络,使master能访问172.31.0.112,要么在metrics deploy加hostNetwork: true,把metrics暴露出来。
1 | I0816 07:07:46.175439 5 controller.go:105] OpenAPI AggregationController: Processing item v1beta1.metrics.k8s.io |
参考:
Kubernetes实录(13) Kubernetes部署metrics-server
HPA
有了metrics就可以开始使用HPA特性了。hpa有几个特点
- deploy或者rs等需要设置resources才能使用hpa
- 如果我们创建一个HPA controller,它会每隔15s(可以通过–horizontal-pod-autoscaler-sync-period修改)检测一次hpa定义的资源与实际资源使用情况,如果达到阀值就会调整pod数量。
- HPA设置的阀值不是绝对的,允许设置一个浮动范围,–horizontal-pod-autoscaler-tolerance默认是0.1
- pod调整算法 desiredReplicas = ceil[currentReplicas * ( currentMetricValue / desiredMetricValue )]
- scale有一个窗口期,期间每次变化会记录下来,选择最优的调整建议再进行scale,这样可以保证资源平滑变动,通过–horizontal-pod-autoscaler-downscale-stabilization设定,默认5分钟。
- 通过hpa调整新增的pod不会马上ready,这时候收集的metrics就不准,为了减少影响,hpa一开始不会收集新pod的metrics。通过–horizontal-pod-autoscaler-initial-readiness-delay(默认30s)和 –horizontal-pod-autoscaler-cpu-initialization-period(默认为 5 分钟)调整

示例hpa.yml:
1 | apiVersion: autoscaling/v2beta2 |
上面的示例包括cpu和memory指标,averageUtilization这个百分比是根据deployment的resources.requests计算的。例如有deployment限制requests是512Mi,replicas是2,实际pod1用了612Mi,pod2用了598Mi,计算公式是 (612+598)/2/512 = 118%
查看hpa的情况,targets第一个是memory,第二个是cpu指标,REPLICAS是根据计算后的当前pod数
1 | ubuntu@k8s-m1:~/k8s/hpa$ kubectl get hpa |
本来想memory使用平均值target.averageValue,而不是百分比的,不过targets显示
/800Mi ,后续再测试
官方示例还包括packets-per-second、requests-per-second这些指标,需要进一步验证
1 | apiVersion: autoscaling/v2beta1 |
结尾
HPA的能力的确很吸引人,如果能自己根据业务特性开发出customer metrice那对运维来说就太方便了,从资源使用的角度来看如果未来HPA能实现node节点的上下架,结合国内云商使用,从资费上更能体现出自动化运维的价值。